Designing Private AKS Access: VPN, DNS, and Hub-Spoke Networking
1. Private AKS Was a Security Decision With Operational Consequences
In the previous posts, I wrote about the Azure landing zone and the platform model that sat on top of it. This is the part where those decisions became real. Private AKS networking was one of the most demanding pieces of the platform, not because AKS itself was especially difficult to provision, but because the moment you decide the control plane should not be publicly reachable, you stop having a simple cluster problem and start having a network design problem.
That decision was not made for aesthetics. The broader Azure environment was being designed around controlled access, private networking, and clear security boundaries between workloads, shared services, and administrative paths. A public Kubernetes API endpoint would have cut across that model. Even if the cluster was still protected with RBAC and identity controls, the operating assumption would have been very different: the control plane would be on the internet, and the main question would be who can authenticate to it. In our case, the stronger requirement was that the control plane should not be publicly exposed in the first place.
That sounds straightforward when written in an architecture document. In practice, it changes almost everything around the cluster. The API server still has to be reachable by the people and systems that operate it. DNS still has to resolve. Routes still have to exist. Peering still has to carry traffic where it needs to go. Operators still need a workable access path from outside Azure. On-premises systems, VPN-connected engineers, shared hub services, and workload spokes all become part of the story.
This is the part of cloud networking that tends to get flattened into diagrams. A private AKS cluster is often described as if it were the same cluster with public access toggled off. It is not. The day you remove the public endpoint, you inherit responsibility for every path by which that cluster will ever be reached.
That is why I see this area as such a strong differentiator in platform work. Plenty of engineers can create an AKS cluster. Far fewer are comfortable owning what happens when the control plane is private, DNS spans multiple networks, engineers connect over VPN, and the cluster becomes unreachable even though Azure insists everything is healthy.
2. What Private AKS Actually Changes
With a public cluster, the access story is comparatively simple. The Kubernetes API is reachable over a public endpoint, and the main controls sit at the identity and authorization layers. You still need to think about RBAC, API exposure rules, IP restrictions if you use them, and how cluster credentials are handled, but the network path itself is not usually the main source of friction. A laptop on the internet can reach the endpoint if policy allows it.
Private AKS changes that shape completely. The cluster API becomes reachable only over private network paths. That means cluster administration is no longer just a Kubernetes concern. It is tied to VNet design, peering, route propagation, DNS resolution, VPN access, and hybrid connectivity if the wider environment includes on-premises systems.
This is where people often underestimate the work. The cluster can be provisioned successfully and still be functionally inaccessible from the places that matter. The node pool can come up. The control plane can be healthy. The Azure resource can show no visible faults. And yet kubectl still fails because the private FQDN does not resolve on the engineer's machine, the route from the VPN client never reaches the spoke, or the name resolves to the right address but the traffic has no valid path back.
That distinction became important very quickly. The cluster was not the problem. The path to the cluster was the problem.
A simplified version of the AKS side looked roughly like this:
resource "azurerm_kubernetes_cluster" "workload" {
name = "aks-workload-nonprod"
location = azurerm_resource_group.aks.location
resource_group_name = azurerm_resource_group.aks.name
dns_prefix = "aks-workload-nonprod"
private_cluster_enabled = true
private_dns_zone_id = azurerm_private_dns_zone.aks_api.id
default_node_pool {
name = "system"
vm_size = "Standard_D4s_v5"
node_count = 3
vnet_subnet_id = azurerm_subnet.aks_nodes.id
}
identity {
type = "UserAssigned"
identity_ids = [azurerm_user_assigned_identity.aks.id]
}
network_profile {
network_plugin = "azure"
network_policy = "azure"
}
}
The important part was not the exact resource block. It was that the cluster was deliberately placed into a spoke subnet, the control plane was made private from the start, and the cluster was tied to a custom private DNS zone instead of treating name resolution as something to sort out later. In a real deployment, that identity also needs the right permissions on the private DNS zone and network resources.
Private AKS also forces you to separate two conversations that are often mixed together. One is control-plane access: how administrators, automation, or debugging tools reach the Kubernetes API. The other is application exposure: how workloads running inside the cluster are reached by other services, users, or external systems. Keeping the control plane private does not automatically mean every application endpoint is private. Those are separate decisions with separate security and networking implications. Treating them as one problem is a reliable way to make the architecture harder to reason about.
What private AKS really did was expose the quality of the surrounding network design. If hub-and-spoke, VPN, DNS, and address planning are sound, private clusters fit naturally into that model. If those pieces are vague, private AKS makes the vagueness impossible to ignore.
3. The Architecture I Built Around It
The network model was based on hub-and-spoke, but not inside a single subscription. The hub VNet lived in a dedicated connectivity or platform subscription and acted as the central place for shared network services. That included the VPN entry point, the core routing patterns, and the DNS components that needed to be shared across environments. Workload VNets lived in spokes in separate subscriptions, typically split by environment and ownership so that development, staging, production, and shared platform domains could remain isolated in ways that matched governance and responsibility.
Private AKS clusters sat in workload spokes rather than in the hub. That part was intentional. The hub was there to provide common network capabilities and controlled connectivity, not to become the place where application runtimes accumulated. Each cluster belonged with the workload environment it served. That kept blast radius and ownership cleaner, and it aligned better with the rest of the Azure operating model.
Those spokes were peered back to the hub. The peering design was not there only for east-west traffic between VNets. It was also what made centralized access and name resolution workable across subscriptions. The goal was simple: connect once to the point-to-site VPN in the platform subscription, then reach any private AKS control plane that lived in the peered spoke subscriptions without maintaining separate VPN entry points per environment. Once the VPN gateway, DNS infrastructure, and shared controls are centralized, the spokes need a dependable way to use them without re-creating the same components in every environment.
The access story then became layered. Routine deployments did not rely on engineers opening direct cluster sessions from their laptops. GitLab CI/CD and GitOps already handled the normal path for application delivery. Direct access was mainly for cluster administration, deeper troubleshooting, and those moments where platform engineers need to inspect the runtime directly rather than infer it from pipelines and dashboards.
DNS became part of the architecture rather than an afterthought. Private DNS zones and a centralized DNS strategy were necessary to make the AKS private API FQDN resolvable from the right places. In a more complex environment, that also pushed us toward a hub-centered resolver pattern rather than leaving every spoke or connected client to solve name resolution independently.
One useful lesson here is that hub-and-spoke diagrams are often too neat. The real architecture is not just hub, spoke, and lines between them. It is the sum of what those lines carry: route propagation, gateway usage, DNS queries, private endpoint access, and administrative traffic. Private AKS forces you to care about all of that.
4. Why I Chose VPN Access Over Public Endpoints or a Jumpbox
Once the control plane is private, the next question is how humans actually reach it. There are only a few realistic options. You can expose the API publicly after all, which defeats the design goal. You can force administrative access through a jumpbox or bastion-style machine inside Azure. Or you can give approved operators a private network path from their own workstation into the environment.
Public API access was the easiest option technically and the wrong one architecturally. It would have created a clean short-term answer by weakening the very control we were trying to introduce. That was not a serious option for this environment.
Using a jumpbox was more realistic and is a pattern many teams fall back to. It has some advantages. The machine sits inside the network, the tooling can be controlled centrally, and the cluster can remain private. But it also creates its own problems. The operational experience gets worse quickly when every non-routine debugging step has to happen through a shared remote host. Tooling drifts. Session state accumulates. File handling becomes awkward. DNS testing becomes less honest because you are no longer seeing what the operator machine sees. And in practice, jumpboxes tend to become semi-permanent shortcuts for work that should have clearer access patterns.
I preferred VPN for the primary administrative path. The model we used centered on an Azure VPN Gateway in the hub, with point-to-site connectivity through the Azure VPN Client for the engineers who genuinely needed cluster-level access. In practical terms, that meant an approved operator could establish a private path from their workstation into the hub-and-spoke environment and work against the cluster as if they were inside the network, while still keeping the API private.
The choice of a VPNGW2 tier was not about chasing a premium SKU for its own sake. It was a pragmatic middle ground for a platform that needed to support real operator access, hybrid connectivity considerations, and enough headroom that the gateway itself would not immediately become the next bottleneck. Networking decisions should leave some room for growth. If a design works only at the exact moment it is drawn, it usually does not work.
In Terraform, the hub-and-spoke access path depended less on the AKS resource itself and more on getting peering behavior right. In the real environment, those peerings often crossed subscription boundaries even though the example below keeps the code simplified:
resource "azurerm_virtual_network_peering" "hub_to_spoke" {
name = "hub-to-aks-spoke"
resource_group_name = azurerm_resource_group.hub.name
virtual_network_name = azurerm_virtual_network.hub.name
remote_virtual_network_id = azurerm_virtual_network.aks_spoke.id
allow_virtual_network_access = true
allow_forwarded_traffic = true
allow_gateway_transit = true
}
resource "azurerm_virtual_network_peering" "spoke_to_hub" {
name = "aks-spoke-to-hub"
resource_group_name = azurerm_resource_group.spoke.name
virtual_network_name = azurerm_virtual_network.aks_spoke.name
remote_virtual_network_id = azurerm_virtual_network.hub.id
allow_virtual_network_access = true
allow_forwarded_traffic = true
use_remote_gateways = true
}
That was one of the easiest places to make the environment look connected while still breaking the real operator path. A successful VPN session did not help much if the spoke could not actually use the hub gateway the way the design assumed. The whole point of the model was to let operators use one centralized VPN in the hub subscription and still reach clusters in multiple spoke subscriptions.
What mattered just as much as the gateway choice was the operating model around it. Not everyone needed VPN-based cluster access. In fact, most people should not have it. Normal deployments still moved through GitLab and ArgoCD. VPN access existed for the people responsible for platform operations, deeper debugging, and controlled administrative work. That distinction kept the access story cleaner and aligned with the broader principle of self-service for routine changes and tighter access for control-plane operations.
The client profile mattered too. A point-to-site tunnel is only half the answer if the connected machine is still asking the wrong DNS servers or lacks the routes for the spoke address space. One of the recurring lessons in this work was that "connected to VPN" and "able to operate the cluster" are not the same thing.
There was still room for a jumpbox as a break-glass or comparison tool, especially when isolating whether a problem was on the operator machine, the VPN path, or inside Azure itself. But it was not the primary interface. If private networking only works reliably from a manually maintained jump host, then the access model has not really been solved.
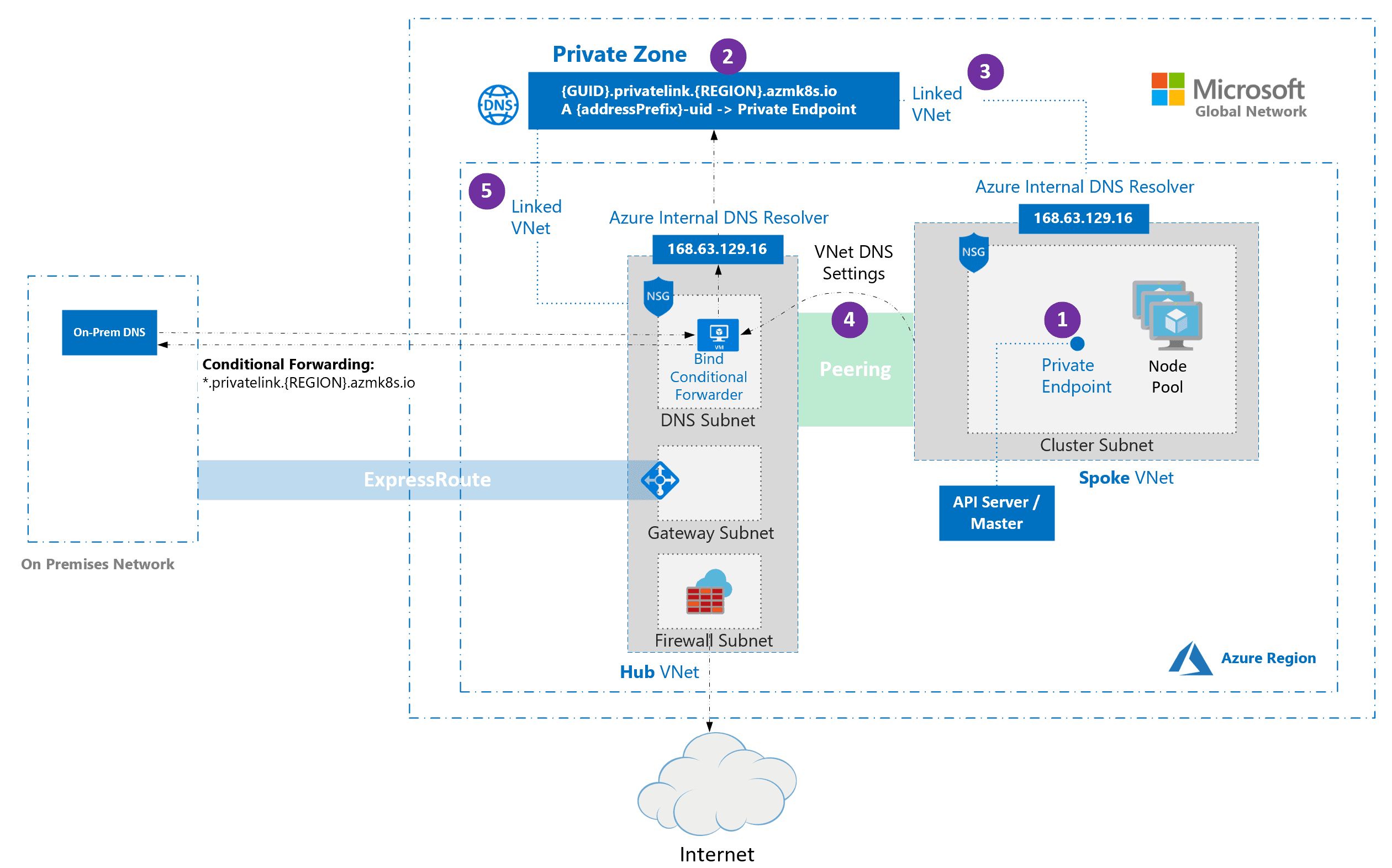
5. DNS Is Where Private AKS Stops Being Simple
DNS was the part that separated a private AKS diagram from a working private AKS platform.
On paper, the AKS control plane has a private FQDN and a private endpoint. In conversation, that often gets compressed into "the cluster is private." What matters operationally is that the right machines, in the right networks, need to resolve that FQDN to the right private address every time. If they cannot, the cluster may as well not exist for them.
This becomes more complicated the moment you move beyond a single VNet. In a hub-and-spoke design, the cluster lives in a spoke. Administrators may connect through a VPN terminating in the hub. Shared services may also live in the hub. Other workloads may be in separate spokes. On-premises DNS infrastructure may still exist. Peering does not magically solve name resolution across all of that. Private DNS only feels transparent when the environment is small enough that its assumptions have not been tested yet.
The AKS private API FQDN problem usually shows up in one of two ways. Either the name does not resolve at all from the place you are testing, or it resolves differently depending on where the query originated. Both are dangerous because they create the illusion that the cluster is "sometimes available" when the real issue is that the DNS path is inconsistent.
To make this reliable, private DNS had to be treated as shared infrastructure rather than as a side effect of cluster creation. Private DNS zones had to be linked deliberately where needed. DNS forwarding had to be explicit. In a multi-VNet and hybrid environment, the resolver path mattered just as much as the zone itself. In other words, the private DNS zone was necessary, but in this design it was not sufficient on its own.
That is what pushed the design toward a centralized DNS model in the hub. Instead of letting every spoke or connected client improvise, the environment benefited from having a clear place where private resolution was handled. Azure DNS Private Resolver became part of that answer. With a resolver pattern in the hub, it becomes much easier to define how on-premises systems, VPN-connected clients, and peered networks find private names in Azure without duplicating custom behavior in too many places. That was especially important because the design goal was not access to one cluster in one VNet, but consistent access from one hub to private AKS clusters spread across multiple spoke subscriptions.
The private DNS zone side looked roughly like this:
resource "azurerm_private_dns_zone" "aks_api" {
name = "privatelink.westeurope.azmk8s.io"
resource_group_name = azurerm_resource_group.connectivity.name
}
resource "azurerm_private_dns_zone_virtual_network_link" "hub" {
name = "hub-link"
resource_group_name = azurerm_resource_group.connectivity.name
private_dns_zone_name = azurerm_private_dns_zone.aks_api.name
virtual_network_id = azurerm_virtual_network.hub.id
}
resource "azurerm_private_dns_zone_virtual_network_link" "aks_spoke" {
name = "aks-spoke-link"
resource_group_name = azurerm_resource_group.connectivity.name
private_dns_zone_name = azurerm_private_dns_zone.aks_api.name
virtual_network_id = azurerm_virtual_network.aks_spoke.id
}
This was the kind of configuration that made the difference between "the cluster exists" and "the cluster can actually be reached from the places that matter." But in this model, zone links alone were not enough. VPN-connected clients and the wider DNS estate still needed a clear resolver path into Azure from the hub.
A simplified version of the resolver side looked like this:
resource "azurerm_subnet" "dns_inbound" {
name = "snet-dns-inbound"
resource_group_name = azurerm_resource_group.connectivity.name
virtual_network_name = azurerm_virtual_network.hub.name
address_prefixes = ["10.10.10.0/28"]
delegation {
name = "dns-resolver"
service_delegation {
name = "Microsoft.Network/dnsResolvers"
actions = ["Microsoft.Network/virtualNetworks/subnets/join/action"]
}
}
}
resource "azurerm_private_dns_resolver" "hub" {
name = "hub-dns-resolver"
resource_group_name = azurerm_resource_group.connectivity.name
location = azurerm_resource_group.connectivity.location
virtual_network_id = azurerm_virtual_network.hub.id
}
resource "azurerm_private_dns_resolver_inbound_endpoint" "hub" {
name = "hub-inbound-endpoint"
private_dns_resolver_id = azurerm_private_dns_resolver.hub.id
location = azurerm_resource_group.connectivity.location
ip_configurations {
private_ip_allocation_method = "Dynamic"
subnet_id = azurerm_subnet.dns_inbound.id
}
}
That inbound endpoint was what gave the hub a stable DNS entry point for VPN-connected clients and existing DNS servers. In a broader hybrid setup, outbound endpoints and forwarding rules can also sit alongside it, but the main architectural point here was that the private AKS zone and the resolver path had to be designed together.
In practical terms, that meant the existing DNS estate had to participate. On-premises resolvers needed conditional forwarding for the relevant private zones, and VPN-connected clients needed to use a DNS path that could actually answer private Azure names. Without that, the cluster might resolve correctly from one network and disappear from another even though nothing about AKS itself had changed.
The practical value of this is hard to overstate. Without a consistent resolver path, debugging cluster access becomes guesswork. A name can resolve inside one spoke, fail on a VPN-connected laptop, work on a jumpbox, fail from a peered VNet, then appear to work again because a local cache still holds a stale answer. That is not really an AKS problem. It is a DNS operating model problem.
Private AKS made that impossible to ignore. The cluster API was one of the cleanest examples of why DNS has to be designed, not assumed.
6. Concrete Problems I Actually Had to Solve
This is where private AKS networking stopped being architectural theory and turned into real platform engineering work. The interesting problems were rarely "Can Azure create the cluster?" They were almost always about why a private design that looked correct in a diagram still failed under real usage.
The Cluster Was Healthy, But Nobody Could Resolve Its Name
One of the first recurring issues was that the cluster existed, the node pools were healthy, the private control plane had been created, and yet operators still could not reach it. The failure mode was not dramatic. kubectl simply failed because the private API FQDN did not resolve from the place the engineer was working.
This is the sort of problem that wastes time because it looks like a cluster problem until you prove otherwise. The natural reaction is to inspect the AKS deployment, check role assignments, or assume the cluster provisioning did not finish cleanly. In reality, the control plane was fine. The broken piece was that the DNS path between the operator and the cluster had never truly been established.
In a private setup, it is not enough that the zone exists somewhere in Azure. It has to be reachable through the actual resolver path used by the calling machine. That is where cross-VNet resolution becomes very real. A peered network is not automatically a correctly resolving network. A VPN-connected laptop is definitely not one unless you make it one.
The fix was to stop thinking about name resolution as local to the cluster deployment and start treating it as part of the shared network architecture. The zone linkage and forwarding model had to be explicit. Queries needed to follow a resolver path that made sense from the hub, from the spokes, and from the VPN-connected client. Once that was made consistent, the issue stopped looking mysterious. Before that, it was easy to lose time investigating the wrong layer.
The VPN Was Connected, But the API Server Still Timed Out
Another common failure mode was even more misleading. DNS would resolve correctly, which made everyone feel closer to the answer, but the API server still timed out from the operator machine. At that point, people often assume the VPN itself is fine because it connected successfully. That is not a safe assumption.
A connected VPN icon tells you almost nothing about whether the route you need is actually usable.
In a hub-and-spoke model, the access path from a point-to-site VPN client to a private AKS cluster in a spoke depends on more than the gateway existing. Peering configuration matters. Gateway transit matters. Whether the spoke is using remote gateways matters. Address spaces need to be advertised correctly. User-defined routes, if present, need to do the right thing. A single incorrect assumption there is enough to produce a perfectly connected VPN session that still cannot reach the cluster.
This was one of the places where working methodically mattered. Once DNS returned the correct private address, the question changed from "Can I resolve it?" to "Can traffic from this specific source reach that specific destination, and can the return path work?" The fastest way to solve it was to stop staring only at the cluster and start validating the network hop by hop. Testing from a known-good machine inside Azure, then from the hub path, then from the VPN client made it much easier to isolate whether the fault sat in routing, peering configuration, or client-side resolution.
Private networking punishes vague troubleshooting. If you skip layers, you end up changing the wrong thing.
Overlapping CIDR Ranges Turned Into Delayed Pain
CIDR planning was another area where the problems arrived later than the decisions that caused them. A network design can look fine during cluster creation and still become a trap when hybrid connectivity or additional spokes are introduced.
The issue with overlapping ranges is not just that they are theoretically undesirable. It is that they create ambiguity in places where the platform desperately needs clarity. If an on-premises network, a spoke VNet, a VPN client address pool, or the AKS service and pod ranges overlap in the wrong way, traffic starts following paths that are hard to reason about and even harder to debug under pressure.
This kind of problem rarely announces itself cleanly. It tends to show up as intermittent reachability, routes that look correct from one perspective but not another, or debugging sessions where one engineer can reach a service and another cannot because they are effectively standing on different address assumptions. When a private cluster depends on hub connectivity, VPN access, and cross-environment communication, address space mistakes stop being local mistakes.
That is why I treat CIDR planning as foundational work rather than a spreadsheet exercise. It is much easier to reserve sensible space early than to redesign around overlaps later when clusters, VPNs, and hybrid links already depend on the current plan. If I had to summarize the lesson plainly, it would be this: CIDR debt is real debt. It accumulates quietly and gets expensive at exactly the wrong time.
Debugging the Private Endpoint Was Mostly About Eliminating Assumptions
The hardest part of debugging private endpoints is that many failures look the same from the outside. The API is unreachable. That does not tell you whether the problem is name resolution, route propagation, peering behavior, client-side DNS, NSG policy, a custom route, or a firewall path that is doing something unexpected.
The discipline that helped most was treating the path as a chain that had to be proven one link at a time. Does the private name resolve? Does it resolve to the expected address? From which networks? Does traffic from the source actually have a route to that address? Does the return path exist? Are the relevant peering settings correct? Is the problem still present when tested from a machine known to be inside the right network boundary?
That sounds basic, but it is the difference between debugging and thrashing. In private environments, it is easy to jump to conclusions because the symptom is simply "it does not connect." One of the most useful habits I built in this work was to stop treating the cluster as the first suspect. Very often, the cluster was fine. The environment around it was not.
7. The Model That Ended Up Working
The model that held up best was the one with the fewest hidden exceptions.
AKS clusters lived in workload spokes. The hub handled shared connectivity concerns from a dedicated platform subscription. VPN access terminated centrally through the hub gateway, and the spoke VNets in other subscriptions were designed to use that shared path rather than exposing separate administrative entry points. DNS was treated as a first-class design concern, with a resolver strategy in the hub and private name resolution made explicit instead of accidental. Private DNS zones, resolver endpoints, and forwarding rules were designed to support how operators, spokes, and hybrid paths actually worked, not just how the cluster was created.
That structure also made responsibility clearer. Workload teams did not need to become experts in private DNS resolution or VPN route propagation just to run services on the platform. The platform team owned those shared network decisions. In turn, application teams got a more predictable environment, and the support burden reduced because the same networking questions did not need to be solved from scratch for every cluster or service.
The human access path also became much cleaner. Routine deployments still went through GitOps and did not depend on direct cluster sessions. VPN access existed for the smaller group of people who actually needed it for cluster administration and deeper troubleshooting. That separation made the platform more governable and easier to audit.
Just as important, the working model made troubleshooting repeatable. When private cluster access failed, there was a known path to validate: resolve the name, verify the expected answer, confirm the network path from the current source, compare behavior from a known-good Azure vantage point, then move outward. Good architecture helps prevent incidents. Good operating models help end them.
8. The Trade-Offs Private AKS Introduced
Private AKS was the right choice for this environment, but it was not the cheap choice.
The most obvious trade-off was operational complexity. A public control plane lets you lean much more heavily on identity and authorization as the primary access controls. A private control plane pulls networking into every cluster conversation. Access, debugging, onboarding, and hybrid integration all become more involved because the control plane is now part of a wider private network design.
DNS was the largest recurring cost in that decision. If the resolver path is not clear, cluster access fails in ways that look inconsistent and waste time. That is why I would not recommend private AKS as a default posture for every team regardless of context. If the surrounding platform does not have a real answer for private DNS, peering, VPN access, and route planning, the cluster will inherit those weaknesses immediately.
There was also a trade-off between security posture and ease of access. A public API with strict identity controls and limited source IPs is operationally simpler. A private API is harder to get wrong from an exposure perspective, but only if the rest of the network model is competently designed. Otherwise you trade one kind of risk for another and simply move the pain into day-two operations.
The human access model had similar trade-offs. VPN access gave a better operator experience than forcing everything through a jumpbox, but it also meant the VPN path itself had to be designed and supported properly. That includes route propagation, client configuration, and DNS behavior on the operator machine, none of which can be hand-waved away just because the gateway connected successfully.
What made the trade-off worthwhile was that it aligned with the rest of the platform direction. The environment was already moving toward private connectivity, controlled access, and explicit network boundaries. Private AKS was consistent with that model. It would have been much harder to justify if the rest of the platform still operated as if public control-plane access were the normal answer.
9. What I Would Do Differently
With hindsight, there are a few things I would tighten earlier.
The first is CIDR planning. I would spend even more time upfront reserving address space with future spokes, future regions, VPN client pools, and hybrid connectivity in mind. This is the sort of work that feels overly cautious until it saves you from a redesign later. Once private clusters, route tables, VPN paths, and peering relationships depend on the existing ranges, changing them becomes painful quickly.
The second is DNS ownership. I would define the private DNS and resolver model earlier and more explicitly instead of letting cluster creation and later troubleshooting gradually reveal what the right structure should have been. Private DNS is not support glue around private AKS. It is part of the design. Treating it that way from day one would reduce a lot of drift and a lot of confused debugging.
I would also formalize the validation path sooner. Once you know private clusters are part of the platform, there is no reason to rely on memory for testing. A small, repeatable checklist for name resolution, route validation, peering assumptions, and known-good test points saves a surprising amount of time. When networking fails, the difference between a runbook and a hunch is enormous.
If I were scaling the model further, I would also look earlier at whether Azure Firewall or a stronger centralized egress and inspection pattern should sit more visibly in the design. Not because every private AKS deployment needs maximum network complexity, but because once the environment grows, ad hoc egress and inspection decisions become another source of inconsistent behavior.
I would keep the same core direction, though. The biggest changes I would make are about designing the invisible pieces earlier, not replacing the model itself.
10. Why This Work Mattered
This work mattered because it was not just about creating a Kubernetes cluster. It was about making a private platform operable.
Private AKS networking is one of those areas where platform engineering stops being abstract very quickly. You cannot solve it with pipelines alone. You cannot solve it with a clean Terraform or OpenTofu module alone. You have to understand how routing, DNS, VPN access, private endpoints, and governance interact in a real environment where multiple teams and networks already exist.
That is also why I think this kind of work differentiates platform engineers from people who only want to stay at the tool layer. Networking is where a lot of cloud implementations become vague. People know the words hub, spoke, VPN, and DNS, but the real signal is whether they can explain why a private cluster is healthy and still unreachable, and whether they know how to fix that without turning the design back into a public one.
The platform value here was not that every developer had to understand private DNS zones, gateway transit, or resolver paths. It was the opposite. The platform needed to absorb that complexity so the environment remained secure and usable without every workload team becoming a networking specialist.
The hardest part of private AKS was not creating the cluster. It was making sure the name resolved and the route existed from the places that mattered.
That is the kind of work I increasingly associate with senior platform engineering. Not just provisioning infrastructure, but taking responsibility for the invisible systems around it so other engineers can rely on them without constantly rediscovering how they work.