GitOps in Production
How I made ArgoCD useful without pretending it solved everything
1. GitOps Looked Like the Right Answer
We had a problem that pipelines could not solve.
Deployments could be technically successful without making the environment understandable. A pipeline could build an image, run tests, and even deploy cleanly while leaving the most important question unanswered: what is actually running in the cluster right now, and how did it get there?
By the time GitOps became a serious topic, the platform already had most of the pieces covered in the earlier posts. The Azure foundation existed. The AKS platform model existed. Private networking and controlled access were in place. The separation between platform control planes and workload clusters had already been established. GitLab CI/CD already handled builds and a lot of the workflow logic around application delivery. The next problem was not how to push code into a cluster. It was how to make deployments understandable, repeatable, and auditable as the environment grew.
Before GitOps, that ambiguity showed up in familiar ways. Git suggested one thing. The cluster sometimes contained another. Manual changes accumulated because they were convenient in the moment. A quick fix applied with kubectl solved a problem now and created uncertainty later. When something failed, debugging often started with reconstructing state rather than addressing the actual issue.
GitOps was appealing because it offered a cleaner answer. Put desired state in Git. Let ArgoCD reconcile the cluster toward that state. Stop treating the cluster as the place where truth lives by accident. That promise was strong enough to be worth pursuing.
What mattered later was realizing that GitOps is not automatically good just because the words sound disciplined. Installing ArgoCD is easy. Designing a deployment system around it is where the real work starts.
2. ArgoCD Was Not the Design
One of the first lessons was that saying "we use ArgoCD" does not actually explain much.
It does not tell you where environment-specific configuration lives. It does not tell you how changes move from development into production. It does not tell you whether CI still owns part of the deployment process, whether images are promoted or rebuilt, whether teams touch one repository or several, or how production changes are controlled. It certainly does not tell you whether developers find the system understandable.
ArgoCD is a reconciler. That is useful, but it is not a deployment model on its own.
This was one of the reasons GitOps had to be treated as an operating decision rather than as a tooling milestone. Most of the complexity was not inside ArgoCD. It sat around it: repository structure, promotion paths, CI boundaries, ownership boundaries, how much indirection teams had to tolerate, and what the actual source of deployment truth was supposed to be at each stage.
That is also why GitOps discussions often become strangely unhelpful in practice. People talk about purity before they have settled the operating model. They argue about whether a flow is "real GitOps" before they can answer much simpler questions, like whether the team understands where to make a change or whether production state is easier to reason about than it was before.
I cared a lot less about purity than about clarity.
The platform was not being built from scratch around ArgoCD. GitLab CI/CD already existed and was already doing useful work. It built images, ran tests, handled sequencing, and enforced checks the teams depended on. Replacing that whole layer just to make the architecture look cleaner would have been a mistake.
So the real question was not whether ArgoCD would replace CI. It was where CI should stop and where GitOps should start.
That boundary turned out to be the most important design decision in the whole GitOps model. If CI owns too much, then GitOps becomes a thin decorative layer and the cluster can still drift from what Git suggests should exist. If GitOps is asked to do too much, teams start forcing workflow logic, sequencing, and build concerns into a tool that was not designed for them. Neither extreme is good.
The hybrid nature of the environment made this a practical decision rather than a philosophical one. Good platform design has to meet the system where it actually is.
3. What GitOps Solved Immediately
Even with those constraints, GitOps solved several problems quickly.
The biggest one was drift.
Without GitOps, the cluster has a habit of becoming the real source of truth even when nobody intends that. A manual fix is applied under pressure. A pipeline updates something indirectly. A configuration change lands in one environment and not another. Over time, the repositories stop being dependable representations of runtime state. At that point, the operational cost is not just technical. It is cognitive. Engineers stop trusting what they read, and every issue begins with checking whether the environment is really what it claims to be.
GitOps improved that immediately because it made declared state matter again. ArgoCD continuously compared what the cluster was running with what Git said it should be running. That did not eliminate every source of complexity, but it did make silent drift much harder to ignore.
One recurring pattern made that concrete. A production issue would be mitigated with a direct kubectl change because speed mattered more than elegance in the moment. The service would recover, but the fix lived only in the cluster. Git still described the old state, so the next deployment change could quietly overwrite the fix and put everyone back into the same confusion. With ArgoCD in place, that mismatch stopped being invisible. The application was visibly out of sync, which forced a more honest decision: either commit the intended state to Git or accept that reconciliation would move the cluster back.
That changed behavior more effectively than policy language ever did. Hidden state became harder to normalize.
It also improved visibility. Git became a more meaningful place to understand deployment intent. That alone is a significant improvement in a multi-service environment where ad hoc operational knowledge does not scale.
Another benefit was consistency. Once the model settled, deployments followed a more repeatable path: change the right source in Git, let ArgoCD see it, and let the cluster reconcile toward that state. That is much easier to reason about than a mixture of direct deploy steps, pipeline-side mutation, and cluster-side exceptions.
GitOps did not remove the need for good operational judgment. It removed a class of hidden state that had been making that judgment harder.
4. Why Production Needed a Different GitOps Model From Non-Production
One of the important decisions was not to treat all environments the same.
Non-production exists to allow iteration. Production exists to carry consequences. That difference needs to appear not only in RBAC and policy, but in how the deployment model itself behaves.
A naive GitOps setup can accidentally weaken that distinction. If any valid change to Git can propagate quickly and automatically everywhere, then the system is clean in theory and too casual in practice. Production should not feel like a faster version of non-production with more anxious people around it.
The platform already had separate cluster-management boundaries between production and non-production. GitOps needed to reinforce that. Production changes needed clearer ownership, a more deliberate promotion path, and less room for accidental propagation from lower environments. Non-production could remain more flexible because that is where experimentation and iteration belonged.
This mattered more than it first seemed to. GitOps often gets described as if it makes environment promotion obvious. It does not. It makes it possible to model promotion clearly, which is a different thing. Whether you actually do that depends on repository design, ownership, promotion rules, and how many places a team has to touch to move a change forward.
The useful question was not "Are we using GitOps everywhere?" It was "Does production state move through a path that is more disciplined than before?"
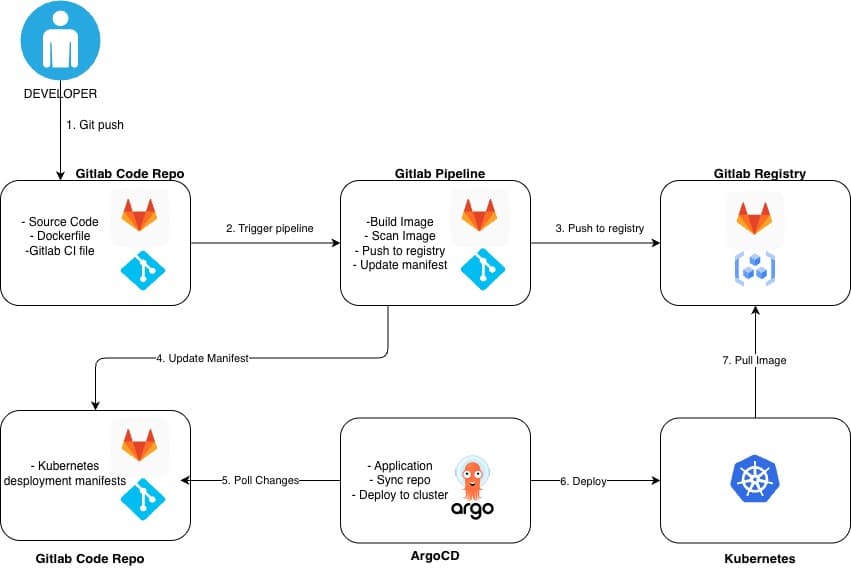
5. The Hybrid Model: GitLab for Workflow, ArgoCD for State
The model that ended up working was not pure GitOps. It was a hybrid, and that was the right answer for this environment.
GitLab CI/CD remained responsible for building images, running tests, enforcing checks, and handling workflow logic. ArgoCD remained responsible for cluster reconciliation and state alignment. That split was not a compromise born of weakness. It was a recognition that CI systems and GitOps controllers are good at different things.
A simplified version of the flow looked like this:
Application code change
-> GitLab CI/CD builds, tests, and publishes an image
-> Desired deployment state is updated in Git for the target environment
-> ArgoCD detects the Git change
-> Target cluster reconciles toward that state
-> Production promotion happens through a separate, deliberate Git change
The repository split mattered just as much as the controller split. In practice, the shape was deliberately boring:
payments-api/
.gitlab-ci.yml
Dockerfile
deploy/
chart/
Chart.yaml
values.yaml
templates/
src/
tests/
platform-gitops/
applicationsets/
workloads.yaml
environments/
nonprod/
azure/
westeurope-01/
payments-api/
values.yaml
aws/
eu-central-1-01/
payments-api/
values.yaml
gcp/
europe-west4-01/
payments-api/
values.yaml
oci/
eu-frankfurt-1-01/
payments-api/
values.yaml
prod/
azure/
westeurope-01/
payments-api/
values.yaml
aws/
eu-central-1-01/
payments-api/
values.yaml
gcp/
europe-west4-01/
payments-api/
values.yaml
oci/
eu-frankfurt-1-01/
payments-api/
values.yaml
The exact names were different, but the pattern was the important part. Application repositories owned code, tests, images, and deployable charts. The GitOps repository owned environment and cluster-specific overrides, promotion, and the ArgoCD definitions that connected those things together. The cluster destinations themselves were registered in ArgoCD separately; the GitOps repo was mapping workloads onto already-known targets, not inventing cluster inventory from scratch. In this kind of model, the same service chart could target AKS, EKS, GKE, and OKE while keeping the per-cloud differences mostly inside environment values.
Promotion also was not a single fan-out change to all four clouds at once. The same image digest usually moved through a smaller rollout ring first, then into broader production targets through separate Git changes, which kept validation and blast radius much easier to reason about.
At that scale, the Git-owned deployment state usually looked less like custom control-plane YAML and more like ordinary environment values that CI updated through a merge request when a release was promoted. The file below is one concrete example for Azure production; the same pattern existed for AWS, GCP, and OCI with cloud-specific differences kept in their own environment paths rather than hidden inside CI logic:
# platform-gitops/environments/prod/azure/westeurope-01/payments-api/values.yaml
global:
environment: prod
cloud: azure
region: westeurope
cluster: azure-westeurope-01
image:
repository: registry.xxxcompany.com/commerce/payments-api
digest: sha256:2e8f1a317b4f6dc5c53fd3a5f0a9f9d6f73be3dc11d2a6b5bb48d03e8a0ab912
autoscaling:
enabled: true
minReplicas: 6
maxReplicas: 18
targetCPUUtilizationPercentage: 70
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
cpu: "1"
memory: "2Gi"
ingress:
enabled: true
className: istio-internal
hosts:
- host: payments.prod.eu.xxxcompany.com
paths:
- path: /
pathType: Prefix
externalSecrets:
enabled: true
secretStoreRef:
name: prod-cluster-secrets
podDisruptionBudget:
minAvailable: 4
Equivalent files existed under environments/prod/aws/..., environments/prod/gcp/..., and environments/prod/oci/... with only the cloud-specific differences changed.
The important part was not that every cloud used identical values. It was that the same release model could be promoted across Azure, AWS, GCP, and OCI while keeping cloud-specific differences explicit and reviewable in Git.
The ApplicationSet layer then generated ArgoCD applications from the environment directories instead of asking teams to handcraft per-cluster Application objects:
apiVersion: argoproj.io/v1alpha1
kind: ApplicationSet
metadata:
name: workloads
namespace: argocd
spec:
goTemplate: true
goTemplateOptions:
- missingkey=error
generators:
- git:
repoURL: https://git.xxxcompany.com/platform/platform-gitops.git
revision: main
directories:
- path: environments/*/*/*/*
template:
metadata:
name: '{{ index .path.segments 4 }}-{{ index .path.segments 1 }}-{{ index .path.segments 2 }}-{{ index .path.segments 3 }}'
labels:
service: '{{ index .path.segments 4 }}'
environment: '{{ index .path.segments 1 }}'
cloud: '{{ index .path.segments 2 }}'
cluster: '{{ index .path.segments 3 }}'
spec:
project: '{{ index .path.segments 1 }}'
destination:
name: '{{ printf "%s-%s" (index .path.segments 2) (index .path.segments 3) }}'
namespace: '{{ index .path.segments 4 }}'
sources:
- repoURL: 'https://git.xxxcompany.com/apps/{{ index .path.segments 4 }}.git'
targetRevision: main
path: deploy/chart
helm:
releaseName: '{{ index .path.segments 4 }}'
valueFiles:
- $values/{{ .path.path }}/values.yaml
- repoURL: https://git.xxxcompany.com/platform/platform-gitops.git
targetRevision: main
ref: values
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=true
- ApplyOutOfSyncOnly=true
revisionHistoryLimit: 3
That is where the phrase "source of truth" becomes useful only if it is precise. Git was the source of desired cluster state. CI was still part of the system that produced deployable artifacts and, in some cases, the changes that moved state forward. That is not a contradiction, but it does mean the system has to be explained honestly.
The hybrid model worked because it made those responsibilities legible instead of pretending everything had become magically simple just because ArgoCD was present.
6. ApplicationSets Helped, but They Raised the Cost of Understanding
As the number of services grew, ApplicationSets became valuable. Managing every ArgoCD application individually does not scale well in a larger microservices environment. Once patterns begin to repeat, a templated way to generate those application definitions becomes useful very quickly.
ApplicationSets helped with onboarding, consistency, and reducing repetitive configuration. That was the upside. The downside was abstraction.
Every new abstraction makes a system more scalable for the people maintaining it and potentially less obvious for the people using it. Once ApplicationSets entered the model, understanding deployments no longer meant understanding only Kubernetes and ArgoCD. It also meant understanding the structure that generated ArgoCD objects in the first place.
That cost showed up most clearly in developer experience. GitOps improved system integrity faster than it improved day-to-day clarity for teams. A developer may now have to understand which repository holds application code, which repository or path holds deployment state, what CI changes automatically, what requires a Git change, and when ArgoCD will actually reconcile the cluster. None of that is impossible. But it is more to hold than "push code and watch a deploy happen."
This is why I do not think GitOps should be discussed only as a control or compliance improvement. The real test is whether teams can use it without losing too much situational clarity. A good platform notices that tension early instead of celebrating the abstraction and leaving teams to deal with the confusion.
7. What GitOps Helped Expose
One of the useful things GitOps did was force ambiguity into the open.
For example, when a service appeared healthy in CI but was not behaving as expected in the cluster, GitOps made it easier to ask the right question: is the declared state wrong, or is the cluster not matching the declared state? That is a much better starting point than trying to reconstruct who applied what by hand.
It also exposed problems in promotion logic. If moving from one environment to another involved too many hidden transformations or too many repositories touched in inconsistent ways, GitOps did not hide that. It made it obvious that the promotion model itself needed work.
Another recurring issue was ownership confusion. If a change involved both CI behavior and GitOps state changes, teams naturally asked which system truly owned deployment intent. That was not a flaw in GitOps so much as a signal that the boundary between workflow and state needed to be explained and, in some cases, simplified.
GitOps also made indirect complexity visible. Multiple repositories, pipeline-generated changes, and ApplicationSet indirection all become more noticeable once the system starts depending on Git as the place where operational truth is supposed to live. That can be uncomfortable, but it is useful. A platform cannot simplify what it refuses to see.
8. What I Changed, and What Actually Matters
The improvements I cared about most were all about clarity.
The first was clearer boundaries between CI and GitOps. CI should own build, validation, and artifact creation. GitOps should own declared deployment state and reconciliation. Once that line gets blurry, the system becomes harder to debug and harder to explain.
The second was a simpler promotion model. Promotion should be explicit, visible in Git, and understandable without cross-referencing too many systems. If moving a change from development toward production feels like chasing state through a maze, the model is too indirect.
The third was reducing unnecessary indirection. More repositories, more layers of generation, and more transformation steps all increase cognitive load. Some indirection is worth it. Too much turns clarity into ceremony.
I would also invest earlier in the developer-facing interface. Teams should not need to understand ArgoCD internals, ApplicationSet behavior, or the entire GitOps control plane to make routine changes safely. That is exactly the sort of complexity a platform should absorb.
None of those changes replace GitOps. They make it easier to live with.
That is also why I am skeptical of GitOps writing that treats the whole topic as a purity contest. The real trade-offs are simpler and harder: more consistency, more auditability, and less drift, but also more abstraction, more indirection, and potentially worse developer experience if the platform does not provide a better interface on top.
In real environments, the question is not whether the system is close to theory. The question is whether it is clearer, safer, and more sustainable than what it replaced.
9. What This Taught Me About GitOps
The most important lesson was that GitOps is not really a tool choice. It is an operating model.
Installing ArgoCD is easy. Designing a deployment system where state is trustworthy, promotion is understandable, responsibilities are clear, and teams can still work effectively is much harder. That is the part that determines whether GitOps reduces ambiguity or merely reorganizes it.
That may be the most practical summary I can give. ArgoCD mattered because reconciliation mattered. But the real success or failure had much more to do with the design around it than with the tool itself.
This also reinforced a broader point from the rest of the series. Platform engineering is rarely about choosing the right tool in isolation. It is about deciding how the system around that tool should work so other engineers can rely on it without having to reverse-engineer it first.
The landing zone work established the boundaries. The AKS and networking work made private Kubernetes operational. The platform design work made Kubernetes usable for application teams. GitOps was the next layer in that same progression. It answered a different question: once the platform exists, how do you make deployment state disciplined enough to trust?
That is why I do not see GitOps as a separate specialty topic. In this environment, it was part of the same platform story. It sat directly on top of the subscription model, the private AKS networking model, the cluster-separation model, and the broader goal of reducing unnecessary infrastructure complexity for application teams.
The result I cared about was not "we use ArgoCD." It was that the deployment model became more understandable, more auditable, and less dependent on hidden cluster state than it had been before.
That is the version of GitOps that is worth talking about in production.